
I've been doing a little bit of dynamically typed programming in Haskell,
to improve
Propellor's
Info type. The result is kind of
interesting in a scary way.
Info started out as a big record type, containing all the different sorts
of metadata that Propellor needed to keep track of. Host IP addresses, DNS
entries, ssh public keys, docker image configuration parameters... This got
quite out of hand.
Info needed to have its hands in everything,
even types that should have been private to their module.
To fix that, recent versions of
Propellor let a single
Info contain many different types of values. Look at it one way and
it contains DNS entries; look at it another way and it contains ssh public
keys, etc.
As an migr from lands where you can never know what type of value is in
a
$foo until you look, this was a scary prospect at first, but I found
it's possible to have the benefits of dynamic types and the safety of
static types too.
The key to doing it is
Data.Dynamic. Thanks to Joachim Breitner for
suggesting I could use it here. What I arrived at is this type (slightly
simplified):
newtype Info = Info [Dynamic]
deriving (Monoid)
So Info is a monoid, and it holds of a bunch of dynamic values, which could
each be of any type at all. Eep!
So far, this is utterly scary to me. To tame it, the Info constructor is not
exported, and so the only way to create an Info is to start with
mempty
and use this function:
addInfo :: (IsInfo v, Monoid v) => Info -> v -> Info
addInfo (Info l) v = Info (toDyn v : l)
The important part of that is that only allows adding values that are in
the
IsInfo type class. That prevents the foot shooting associated with
dynamic types, by only allowing use of types that make sense as Info.
Otherwise arbitrary Strings etc could be passed to addInfo by accident, and
all get concated together, and that would be a total dynamic programming
mess.
Anything you can add into an Info, you can get back out:
getInfo :: (IsInfo v, Monoid v) => Info -> v
getInfo (Info l) = mconcat (mapMaybe fromDynamic (reverse l))
Only monoids can be stored in Info, so if you ask for a type that an Info
doesn't contain, you'll get back
mempty.
Crucially,
IsInfo is an open type class. Any module in Propellor
can make a new data type and make it an instance of
IsInfo, and then that
new data type can be stored in the
Info of a
Property, and any
Host that
uses the
Property will have that added to its
Info, available for later
introspection.
For example, this weekend I'm extending Propellor to have controllers:
Hosts that are responsible for running Propellor on some other hosts.
Useful if you want to run
propellor once and have it update the
configuration of an entire network of hosts.
There can be whole chains of controllers controlling other controllers etc.
The problem is, what if host
foo has the property
controllerFor bar
and host
bar has the property
controllerFor foo? I want to avoid
a loop of foo running Propellor on bar, running Propellor on foo, ...
To detect such loops, each Host's Info should contain a list of the
Hosts it's controlling. Which is not hard to accomplish:
newtype Controlling = Controlled [Host]
deriving (Typeable, Monoid)
isControlledBy :: Host -> Controlling -> Bool
h isControlledBy (Controlled hs) = any (== hostName h) (map hostName hs)
instance IsInfo Controlling where
propigateInfo _ = True
mkControllingInfo :: Host -> Info
mkControllingInfo controlled = addInfo mempty (Controlled [controlled])
getControlledBy :: Host -> Controlling
getControlledBy = getInfo . hostInfo
isControllerLoop :: Host -> Host -> Bool
isControllerLoop controller controlled = go S.empty controlled
where
go checked h
controller isControlledBy c = True
-- avoid checking loops that have been checked before
hostName h S.member checked = False
otherwise = any (go (S.insert (hostName h) checked)) l
where
c@(Controlled l) = getControlledBy h
This is all internal to the module that needs it; the rest of
propellor doesn't need to know that the Info is using used for this.
And yet, the necessary information about Hosts is gathered as
propellor runs.
So, that's a useful technique. I do wonder if I could somehow make
addInfo combine together values in the list that have the same type;
as it is the list can get long. And, to show Info, the best I could do was
this:
instance Show Info where
show (Info l) = "Info " ++ show (map dynTypeRep l)
The resulting long list of the types of vales stored in a host's info is not
a useful as it could be. Of course,
getInfo can be used to get any
particular type of value:
*Main> hostInfo kite
Info [InfoVal System,PrivInfo,PrivInfo,Controlling,DnsInfo,DnsInfo,DnsInfo,AliasesInfo, ...
*Main> getInfo (hostInfo kite) :: AliasesInfo
AliasesInfo (fromList ["downloads.kitenet.net","git.joeyh.name","imap.kitenet.net","nntp.olduse.net" ...
And finally, I keep trying to think of a better name than "Info".
 I have officially published my doctoral thesis Lazy Evaluation: From natural semantics to a machine-checked compiler transformation (DOI: 10.5445/IR/1000054251). The abstract of the 226 page long document that earned me a summa cum laude reads
I have officially published my doctoral thesis Lazy Evaluation: From natural semantics to a machine-checked compiler transformation (DOI: 10.5445/IR/1000054251). The abstract of the 226 page long document that earned me a summa cum laude reads
 What happened in the
What happened in the  Portability toward other systems has been improved: old versions of GNU diff are now supported (Mike McQuaid), suggestion of the appropriate locale is now the more generic
Portability toward other systems has been improved: old versions of GNU diff are now supported (Mike McQuaid), suggestion of the appropriate locale is now the more generic  Nearly 40 participants from 14 different free software project had very busy
days sharing knowledge, building understanding, and producing actual patches.
Anyone interested in cross project discussions should join the
Nearly 40 participants from 14 different free software project had very busy
days sharing knowledge, building understanding, and producing actual patches.
Anyone interested in cross project discussions should join the  Infrastructure
Several discussions at the meeting helped refine a shared understanding of what
kind of information should be recorded on a build, and how they could be used.
Daniel Kahn Gillmor sent a
Infrastructure
Several discussions at the meeting helped refine a shared understanding of what
kind of information should be recorded on a build, and how they could be used.
Daniel Kahn Gillmor sent a 
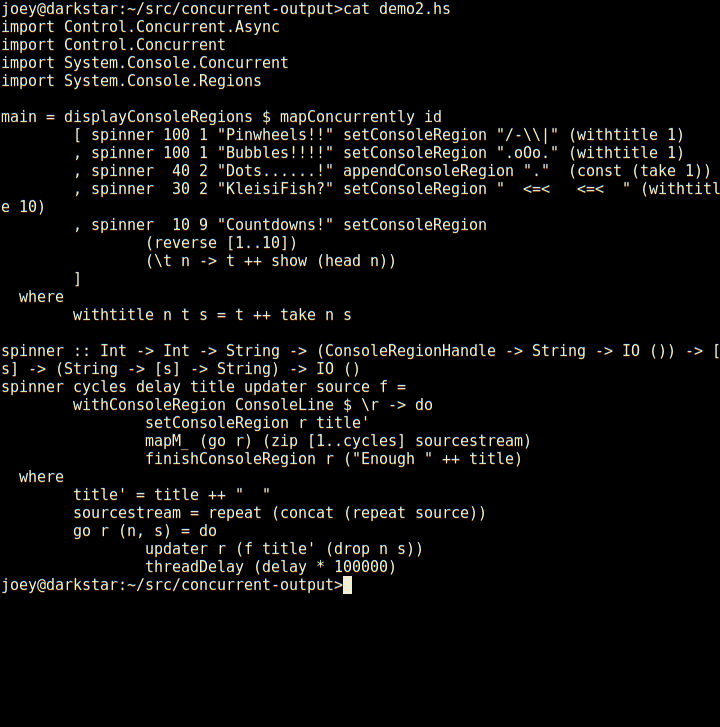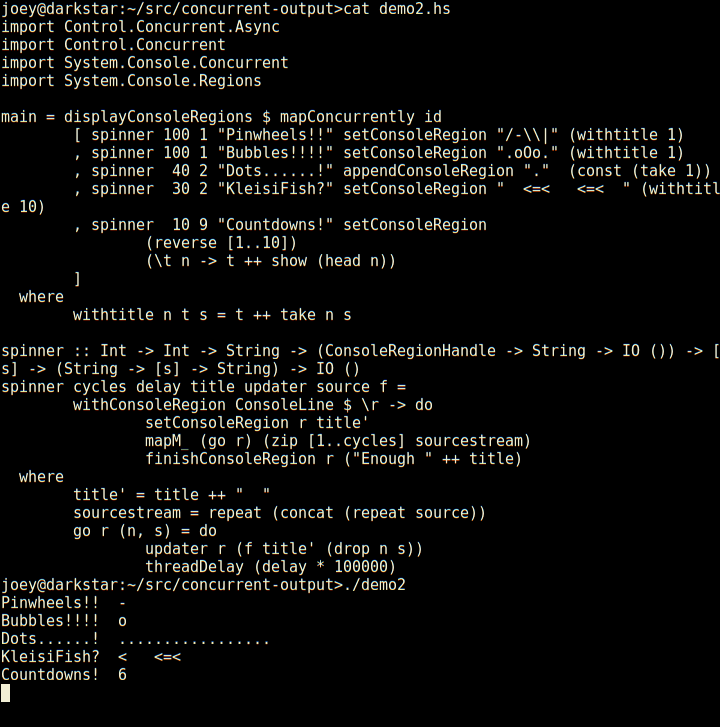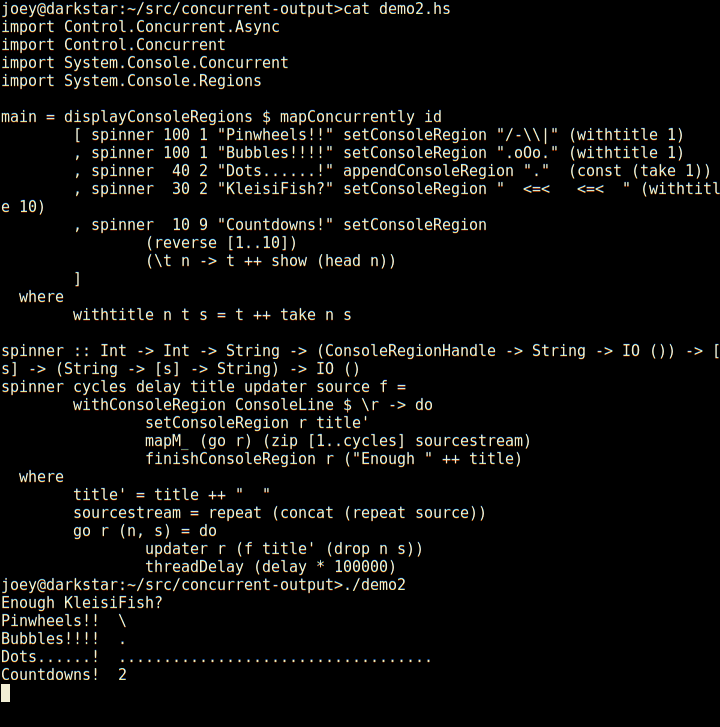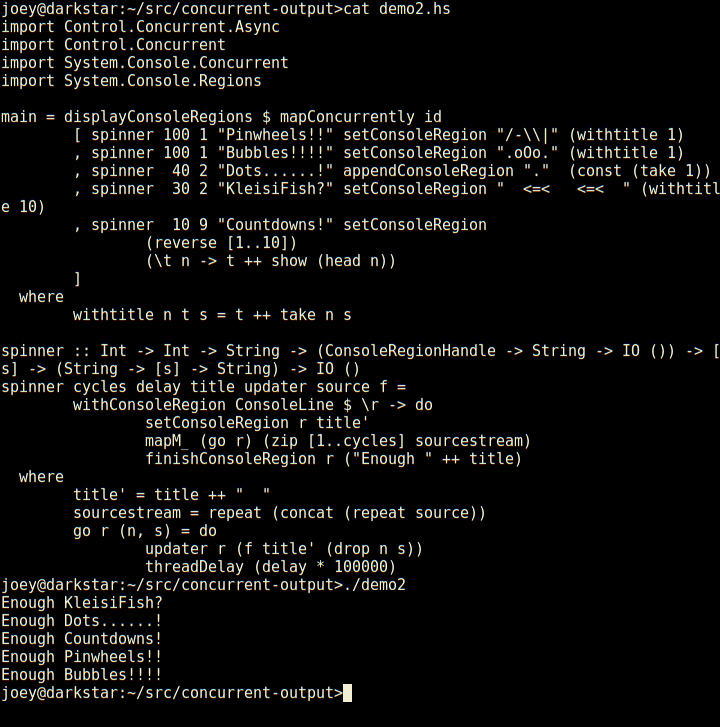 Not bad for 23 lines of code, is that? Seems much less tedious to do things
this way than using ncurses. Even with its panels, ncurses requires you to
think about layout of various things on the screen, and many low-level
details. This, by contrast, is compositional, just add another region and a
thread to update it, and away it goes.
So, here's an apt-like download progress display, in 30 lines of code.
Not bad for 23 lines of code, is that? Seems much less tedious to do things
this way than using ncurses. Even with its panels, ncurses requires you to
think about layout of various things on the screen, and many low-level
details. This, by contrast, is compositional, just add another region and a
thread to update it, and away it goes.
So, here's an apt-like download progress display, in 30 lines of code.
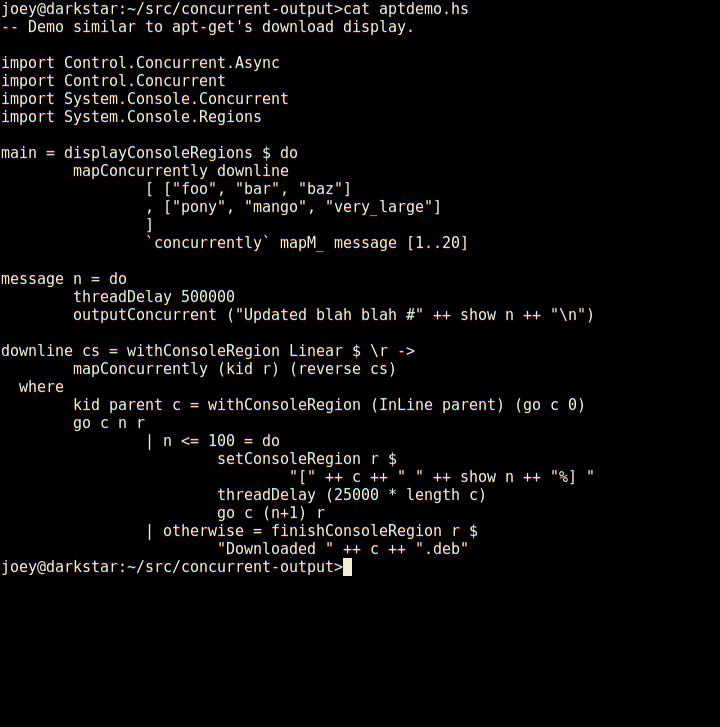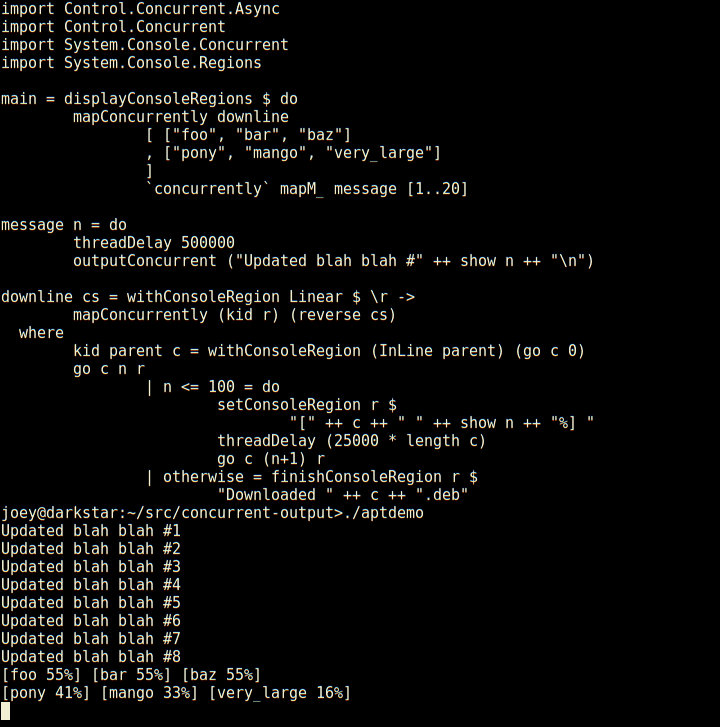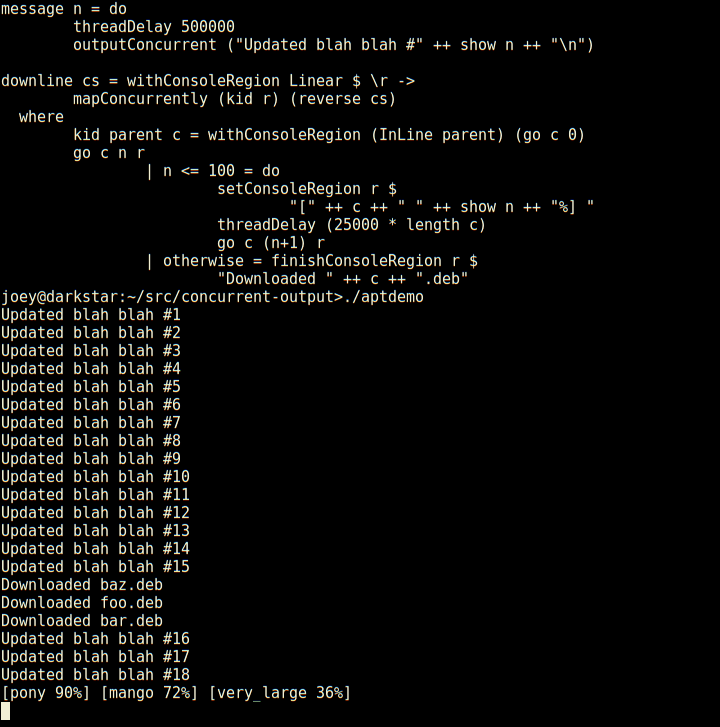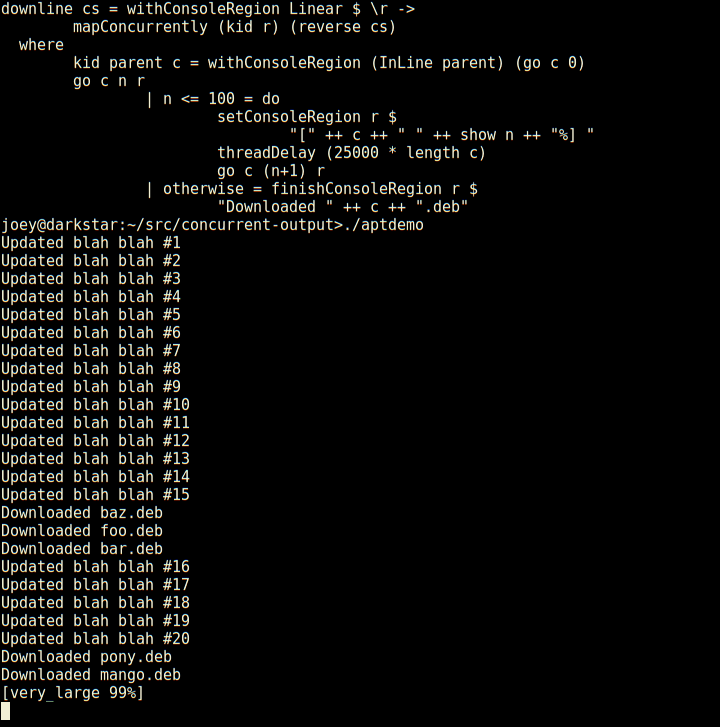 Not only does it have regions which are individual lines of the screen,
but those can have sub-regions within them as seen here (and so on).
And, log-type messages automatically scroll up above the regions.
External programs run by
Not only does it have regions which are individual lines of the screen,
but those can have sub-regions within them as seen here (and so on).
And, log-type messages automatically scroll up above the regions.
External programs run by 
 After
After {kind=link}